

At MarketingExperiments, we endeavor to teach you to bring the process of scientific discovery to your marketing campaigns to learn what your customers really want and improve results. And, to that end, we share experiments (along with successful case studies — 1,470 and counting — from our sister publication, MarketingSherpa).
But we can learn just as much from the stumbles, errors and mistakes we encounter on our journey of customer discovery. Unfortunately, those stories tend to be harder to get. So I want to laud the marketer we are going to discuss today for sharing an example of something that did not work.
Even successful marketers have losses. But the good ones learn from them.
Mary Abrahamson, Email Marketing Specialist, Ferguson Enterprises, is a successful marketer. So successful, in fact, that we recently featured her as the main story in a mini-documentary that highlighted her journey at MarketingSherpa Summit.
But when I recently reached out to her, it wasn’t only a further success she shared, but also a hard-won lesson learned in the trenches of email testing. Let’s take a look at the test, focused around a Black Friday promotion. But first, some background on the overall campaign.
Holiday promotion to B2B customers
This year, Ferguson tried something innovative. Even though it is a B2B company, it tested promotions tied to the holiday shopping season, such as Black Friday and Cyber Monday discounts.
The promotion targeted trade customers with online accounts. Ferguson offered enhanced discounts on a select assortment of products, promoted via email and online only.
The campaign began in early November. “Pre-promotion emails generated a lot of traffic to the Ferguson Online registration page.”
Here is one test that was part of a larger, ultimately successful recruiting effort.
Control
The Control did not show any products.

Treatment
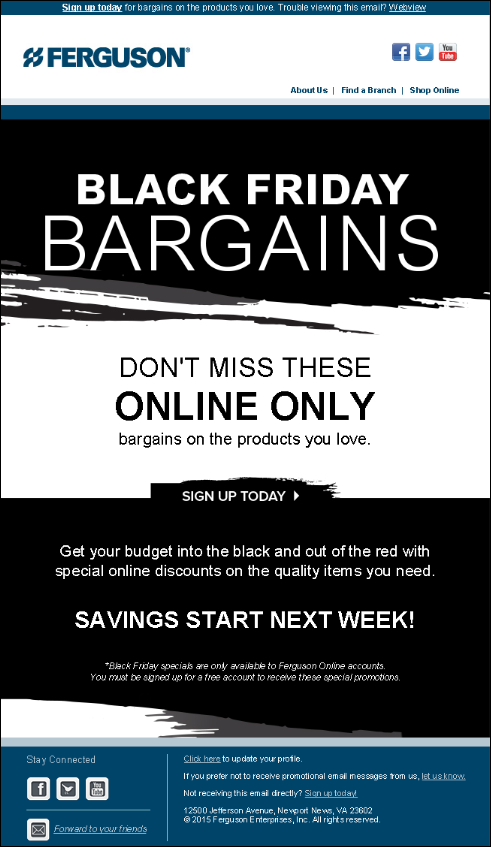
The Treatment showed promotional products, as seen below, behind the “Black Friday Bargains” headline.

Test Results
The unique clickthrough rate for both the Control and Treatment was the same.
Revised Test Results
But wait, there’s more. On Monday, the team realized that the Treatment was actually the winner. Now, with more data collected beyond the first four hours.
This was lift that Ferguson didn’t get by concluding that the wrong email was the winner. “The Treatment, in reality, should have been deemed the winner, and likely would have had the test … run longer,” Mary said.
Why were the initial test results inaccurate?
When you’re running a test, you’re trying to extrapolate future action based on the current actions you can measure. To do that, you need a controlled testing environment, and you need to ensure that what you observe actually represents real-world usage. There are four reasons this may not occur, which are known as test validity threats.
We go into these threats much deeper in the MECLABS Online Testing online course, but I’ll touch on them briefly here, as they relate to this test, so you can lower the chance of picking the wrong treatment as a winner for your own tests.
- Sampling Distortion Effect: The effect on the test outcome caused by failing to collect a sufficient number of observations.
This may have been an issue with Ferguson’s test. Enough samples should be collected to ensure that the behavior observed so far really represents the behavior of all of your audience (as measured by level of confidence). At MECLABS, we shoot for a 95% level of confidence.
For an overly simplistic explanation, if you flip a coin twice, and you get heads both times, it doesn’t necessarily mean you have a two-headed quarter. That could just be random chance. As the number of coin flips increases, however, the law of averages kicks in and — assuming the coin is fair — you should get closer and closer to a 50/50 split. For example, it would take approximately 10,000 flips to be able to say with a 95% level of confidence that a coin has an equal chance of landing on heads or tails.
- History Effect: The effect on a test variable by an extraneous variable associated with the passage of time.
One issue in this test may have been that the Ferguson customers who opened the email on Sunday may be different than those who opened the email during the week.
Most companies have very quick responses to their email. However, for a B2B audience like this, there might be a much longer tail, with people not acting until well into the week.
This type of situation does not happen often, Derrick Jackson, Director of Data Reporting and Analytics, MECLABS, told me.
“With email testing, we often see a vast majority of the responses come in very early in the test. Any data received after the first few days normally does not significantly change the results of the test. Whenever the supplemental data significantly changes the test results (as in this case), we try to go back and identify possible reasons for that. Some possible reasons include: time of email send, urgency messaging (or lack thereof) in one treatment, or list split. These are just some of the possible reasons,” Derrick said.
The time of email send is a likely cause here as the urgency in the messaging was identical. And Mary told me she learned that, “Testing that takes place on Sundays (the day every email was sent — as deals started midnight every Sunday) need a longer time span than usual. Our usual time span for testing is four hours,” Mary said.
A list split issue would tie into our next validity threat …
- Selection Effect: The effect on a test variable by an extraneous variable associated with different types of subjects not being evenly distributed between experimental treatments.
This could be as simple as a list split issue — people who receive your control being very different than people who receive your treatment.
Or it could be (and this ties into the history effect) that people who respond quickly on a Sunday are just different than the entire list.
Science is based on randomized controlled trials. And you want to make sure you aren’t biasing the test by biasing the sample exposed to it.
- Instrumentation Effect: The effect on the test variable caused by a variable external to an experiment, which is associated with a change in the measurement instrument.
This involves an error in the software you were using to measure the test. Or a load time issue that caused one landing page to load much slower than another. Again, you wouldn’t have really observed a difference in the behavior of your customers, and that’s why your results would be skewed. For Mary’s test, there is no reason to believe instrumentation effect had an impact.
How you can avoid these mistakes
The best way to avoid picking the wrong winner is to account for the above validity threats.
However, that isn’t always possible. One of the major likely culprits here was history effect, which is at odds with the need for most businesses to act quickly.
“In a perfect testing environment, we would like to collect email test data for at least a week. Then we would analyze all relevant KPIs (key performance indicators) and make an informed decision on which to send to the broader list. Unfortunately for us, business does not wait for us to conduct in-depth analysis and make the perfect decision every time. We have to be expeditious in our analysis and decision making,” Derrick said.
So here’s the approach Derrick’s team takes …
“To help make quick and accurate decision, we monitor the email data in real time. We track the difference between the rates of the main KPI. Once that difference begins to stabilize we call the test and push the winning treatment. Hopefully a trend will emerge as to how long to collect and analyze the data before calling a test.”
Hopefully that information is helpful for you, but it likely wouldn’t have worked for Mary. So what could she do next time? According to Derrick, her choices would be:
- Wait for one treatment to emerge as a clear optimal winner (remember, the Control and Treatment were tied when the winner was selected)
- Call a winner based on some other metric(s) (Conversion Rate, etc.)
- Split the email to the entire list and analyze the findings from there
“All of these have pros and cons based on the situation,” Derrick said. “The decision on which path to take would be made on an ad hoc basis.”
Full campaign results
This was just one test in an overall campaign, which I am glad to say, has a happy ending. “Over the end of November and first week of December, this initiative accounted for increased traffic to the site, higher than average time on site and a substantial amount in ROI.”
“As an attendee [of a MarketingSherpa Summit], if nothing else I learned from MarketingSherpa that testing absolutely must be part of the email process. From Whirlpool’s learnings on the right mix of CTAs (less is more) to live testing labs during the conference — the power of testing certainly came alive to me,” Mary said.
“Long story short — whether it be a subject line or a content test, our team is making more data-driven decisions and providing more customer-centric content,” Mary concluded.
You can follow Daniel Burstein, Director of Editorial Content, MECLABS Institute, @DanielBurstein.
You might also like
Enter the MarketingExperiments’ fourth annual copywriting contest for a chance to win a MarketingSherpa package, which includes a free ticket to MarketingSherpa Summit 2016 and a stay at the Bellagio in Las Vegas. Deadline for entries in January 17, 2016 and official rules are here.
Validity Threats: How we could have missed a 31% increase in conversions
Online Marketing Tests: How could you be so sure?
Email Marketing Charts: How to effectively build your email list [From MarketingSherpa]
MECLABS Online Testing online source — Learn a proven methodology for executing effective and valid experiments for increased marketing ROI
MarketingSherpa Summit 2016 — At the Bellagio in Las Vegas, February 22-24